Use it yourself, with our team alongside yours, or let us run it for you. For builders and scientists.
REVEAL
Reveal the signals in your data with the biomedical analytics platform that cares about optimizing usability, out-of-the-box functionality, extensibility, and speed—all with the lowest cloud storage and computing costs.
Catalyze your research. Securely. Collaboratively. Reproducibly.
Applications
Extensible application packages that scientists actually want to use, informed by years of close partnerships.
Visually probe complex multimodal longitudinal data sets. Or use science-level APIs that do the heavy lifting by hiding implementation details.
Seamlessly synchronize interactive work by GUI and notebook users.
Portal
Data Catalog
DataTrailTM
Cohort Analytics
Pop. Biobanks
Meta Analysis
BioLensTM
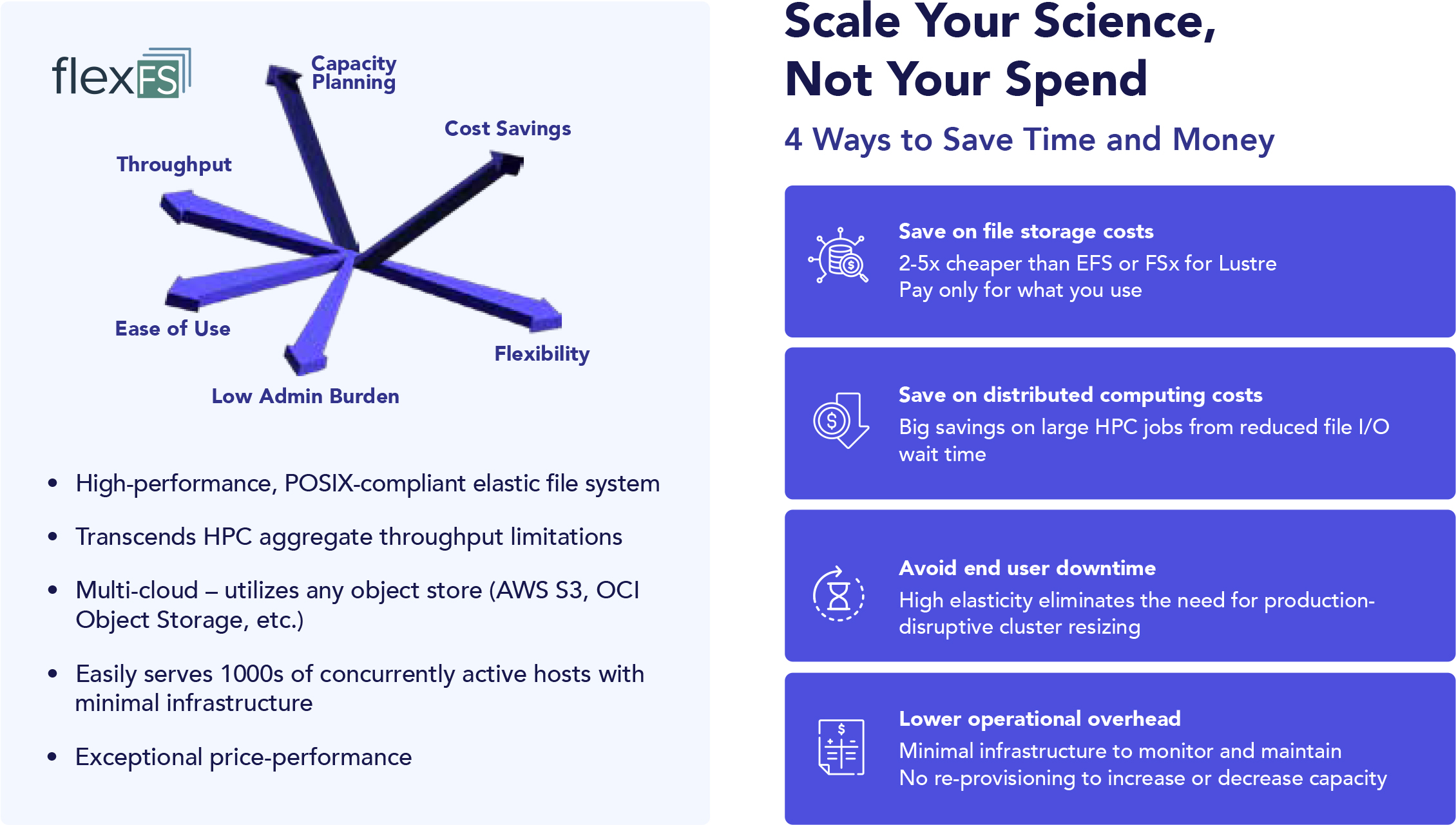
flexFS
Cut cloud storage, cloud computing, and operational overhead costs with flexFS: a POSIX-compliant, highly elastic network file system.
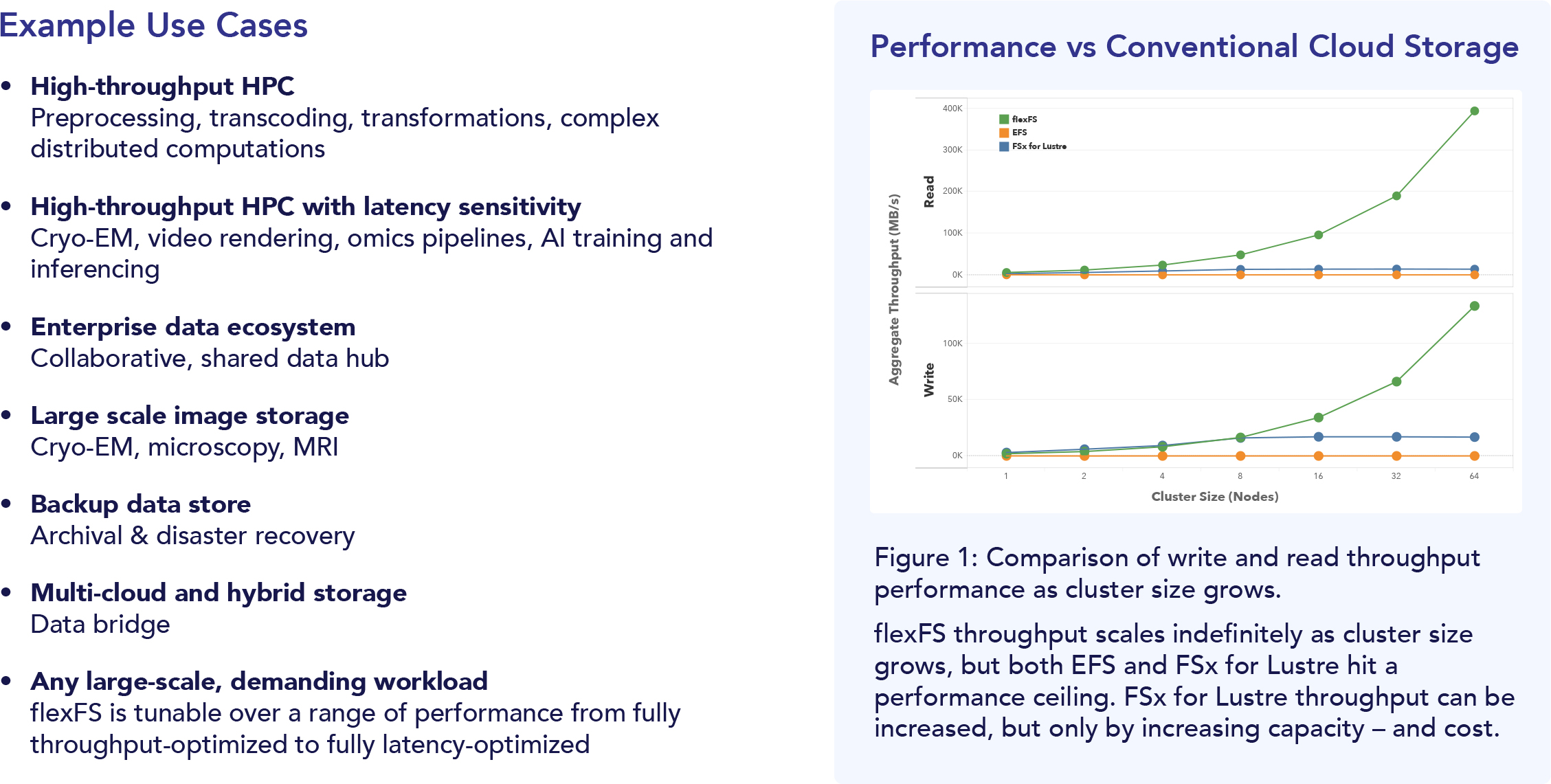
Get cost relief for:
high throughput HPC for ‘omics and AI
scalable image repository for cryo-EM and biomedical images
collaborative, enterprise data ecosystems
hybrid storage
multi-cloud strategies
"What’s made our collaboration with Paradigm4 so enjoyable is that REVEAL is fast, it integrates with tools that the geneticists are really happy to use, and it means that the computational biology group is not a bottleneck for their analysis."
Matt Brauer
Sr. V.P., Data Science
Tech Enabled Services
Services
Accelerate your programs with P4’s Solution Services
We’ll help you get going, get answers, and amplify your team’s productivity.
On time and well developed solutions are the hallmarks of Paradigm4’s customer solutions team.
We deliver as committed Top 10 Pharma Program Manager for a new program: “Paradigm4 knocked this project out of the park and exceeded expectations on timeline and quality of work….you guys have been rock stars on a very challenging project.”
We’re productive In the words of a Technical Product Manager: “I attend so many meetings every week where stuff is run into the ground. It is refreshing to attend these meetings [with P4] where work actually gets done.”
We’re responsive Another top 20 pharma customer said: “You are always quick to respond to issues we have and investigate and prioritize as they come up. You respond faster than other people inside our company.”
Our Team Our Solutions team has extensive experience and advanced degrees in bioinformatics, biomedical engineering, population genetics, image and signal processing, applied mathematics, machine-learning, scalable parallel computing, R, Python, databases, and cloud computing.
flexFS - Supercharged Cloud File System
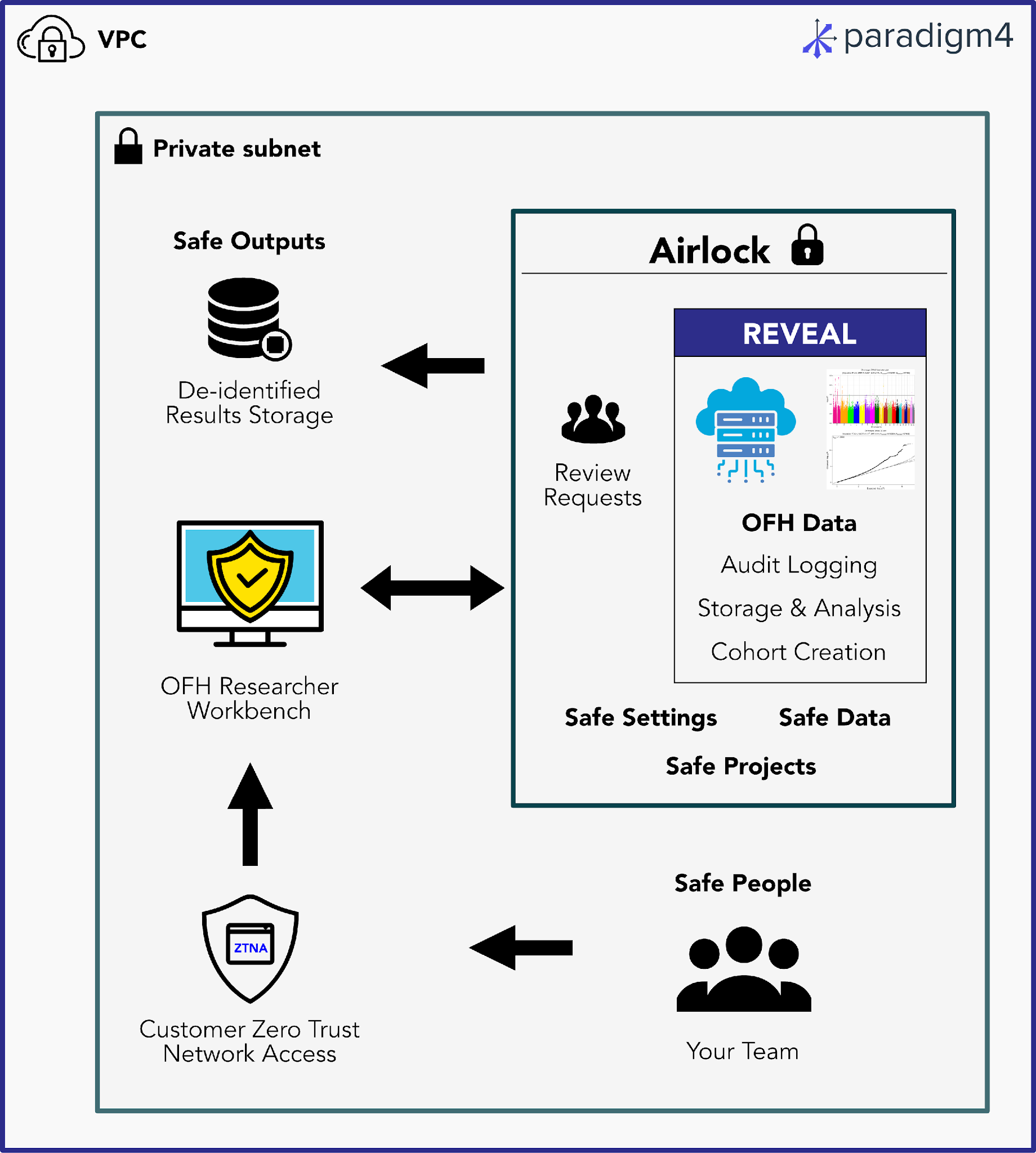
Trusted Research Environment
Solid security and governance are table stakes
Enterprise ready: integrates within existing enterprise governance & security on your VPC
Certified: ISO-27001, 21 CFR Part 11, HIPAA, GDPR
Data Protection: end-end, in transit and at rest encryption for sensitive biomedical data
Controlled Access: fine-grained RBAC permissions
Comprehensive audit trails: provenance with DataTrails and event logs
Secure Collaboration: share workspaces and derived results while protecting sensitive data
Audit Partner: for external audits like Our Future Health